Abstract
We present ARTrackV2, which integrates two pivotal aspects of tracking: determining where to look (localization) and how to describe (appearance analysis) the target object across video frames.
Building on the foundation of its predecessor, ARTrackV2 extends the concept by introducing a unified generative framework to "read out" object's trajectory and "retell" its appearance in an autoregressive manner. This approach fosters a time-continuous methodology that models the joint evolution of motion and visual features, guided by previous estimates. Furthermore, ARTrackV2 stands out for its efficiency and simplicity, obviating the less efficient intra-frame autoregression and hand-tuned parameters for appearance updates. Despite its simplicity, ARTrackV2 achieves state-of-the-art performance on prevailing benchmark datasets while demonstrating remarkable efficiency improvement.
In particular, ARTrackV2 achieves AO score of 79.5% on GOT-10k, and AUC of 86.1% on TrackingNet while being 3.6 times faster than ARTrack.
Our research showcases its unique capability to model continuous variations in both trajectory and target appearance concurrently. Through cohesive techniques encompassing appearance reconstruction and trajectory prediction, we offer comprehensive visualizations of target tracking across intricate and varied scenarios. Our method adeptly captures the nuanced evolution of both trajectory and appearance, demonstrated through video representations and attention maps, establishing its fidelity in representing the dynamic nature of tracked targets.
Architecture
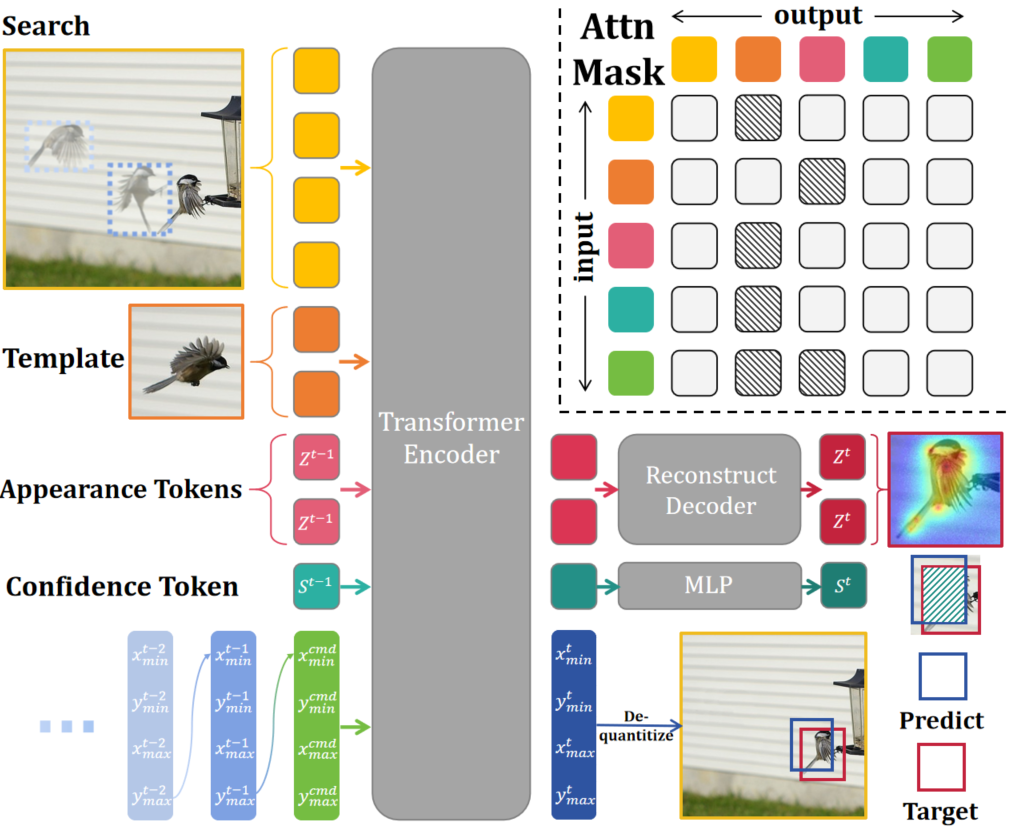
Qualitative Results
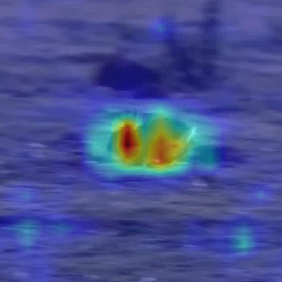
Attention map visualization
We generate cross-attention maps about the appearance tokens to the search region while evolving trajectory and appearance. In order to demonstrate the versatility of our model, we challenge it with complex scenarios that pose significant tracking difficulties.















Search

Time t

Time t+1

Time t+2

Time t+3
Image reconstruction visualization
To offer a more intuitive portrayal of our appearance evolution, distinct from visualizing the cross-attention map within the feature domain between appearance tokens and search, we conduct a quantitative analysis of appearance reconstruction within the image pixel domain. For each video sequence, we show the target’s appearance (top) and reconstructed appearance image (bottom).
















Time t

Time t+N

Time t+2N

Time t+3N

Time t+4N
Video
ARTrackV2 facilitates concurrent tracking and modeling of both target trajectory and appearance. Within a complex tracking environment, we present a series of videos showcasing various elements: tracking results (far left), attention maps illustrating appearance (middle), reconstructed appearance (top right), and target appearance (bottom right). This comprehensive visualization offers insights into our method's capacity to capture and represent the dynamic interplay between trajectory and target appearance.
Related Links
There's a lot of excellent work that was introduced around the same time as ours.
Autoregressive Visual Tracking.
At the core of our methodology lies ARTrack, leveraging sequence-level training and pioneering continuous trajectory modeling to attain superior performance in tracking endeavors.
The codebase for ARTrack has been meticulously organized and is readily accessible within the aforementioned repository, ensuring efficient management and accessibility for users.
SeqTrack: Sequence to Sequence Learning for Visual Object Tracking.
SeqTrack is also a generative tracking method that uses a simple encoder-decoder structure to achieve accuracy comparable to mainstream methods.
The codebase for SeqTrack.
BibTeX
@InProceedings{Bai_2024_CVPR,
author = {Bai, Yifan and Zhao, Zeyang and Gong, Yihong and Wei, Xing},
title = {ARTrackV2: Prompting Autoregressive Tracker Where to Look and How to Describe},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024}
}